Predominantly for the task-oriented visual dialogue systems, the GuessWhat dataset has been in use. However, with the rise in popularity, new datasets have been proposed periodically to further up the game. This post(is part-1, part-2 here) discusses the present-day datasets for these systems.
GuessWhat:
The dataset was first introduced in the paper: Guesswhat?! visual object discovery through multi-modal dialogue
Images: A filtered subset of MS COCO dataset images are used. Images that contain three to twenty objects are only used to ensure the conversation neither trivial nor complex.
In total, 77,973 images consisting of 609,543 objects are used for dataset curation.
Dialogues: Two seperate tasks are created on AMT for the questioner and oracle roles. After pre-processing, validation, final dataset Consists of 155,280 dialogues containing 821,889 question/answer pairs on 66,537 unique images and 134,073 unique objects.
All questions have binary answers (yes/no/na) and distributed as 52.2% No, 45.6% Yes, 2.2% NA
Answers: Binary (Yes/No/NA)
The baseline code is available here
An example from the dataset is shown below

VisDial
The dataset was introduced in the paper: Visual Dialog
Images: Collected from MS COCO dataset. The visual complexity of these images allows for engaging and diverse conversations
Dialogues: Two persons chat on AMT with real-time conversations about the image with the roles of questioner and answerer.
Answers: Not restricted to short/concise, but as naturally and as conversationally possible.
Overall, VisDial contains 1 dialog each (with 10 question-answer pairs) on ∼140k images, for a total of ∼1.4M dialog question-answer pairs.
Dataset can be downloaded from here
The source code for the dataset curation and paper are available here
An example from the dataset is shown below

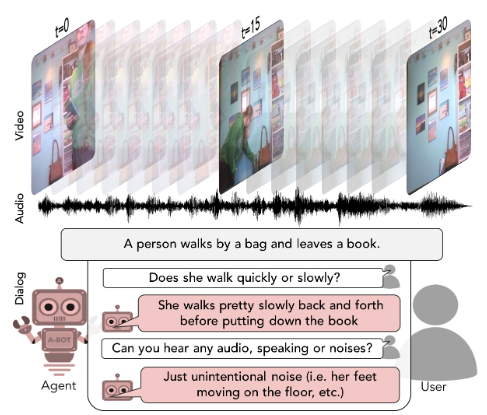
AVSD (Audio Visual Scene Aware Dialog)
The dataset was introduced in the paper: Audio Visual Scene-Aware Dialog
Videos: Collected from Charades human-activity dataset. The visual complexity of these images allows for engaging and diverse conversations
Dialogues: Two persons chat on AMT with real-time conversations about the events in the video with the roles of questioner and answerer.
Answers: Provides as detailed answers as possible.
Overall, ACSD dataset contains 11816 conversations (7985 training, 1863 validation, and 1968 testing), each including a video summary. There are a total of 118,160 question/answer (QA) pairs
Dataset can be downloaded from here
The baseline code is available here
An example from the dataset is shown below
#datasets #visual #dialog #task-oriented