Who am I? is a popular guessing game where the players use yes/no questions to guess the identity of person/animal/place. Visual object discovery mimics the game with two players (oracle and questioner) through dialog. In this blog post, lets dive into the introductory paper where GuessWhat?! dataset was introduced.
Contributions:
- Introduced the dataset, GuessWhat, a testbed for task-oriented systems. The paper discusses in detail on dataset curation, used filterings, curation of dialogues
- Proposed goal-directed task for multimodal dialogue
Game Play:
- Oracle:
- Randomly assigns an object in the scene
- Replies yes/no/na for the questions
- NA is used if the question asked is ambiguous/complex
- Questioner:
- Core idea: Ask informative questions, minimize the number of questions required
- Not aware of the list of objects in the scene
- After gathering enough evidence, guesses the object
- Locating the object correctly is treated as successful game otherwise unsuccessful
- Has two sub-tasks (i) Question Generator - Generates the question to ask (ii) Guesser - Based on the answers received, guesses the object. Question Generator and Guesser are trained independently
- Question Generator:
- Spatial Reasoning: Ideniify based on where the object is located. Bottom left corner, Top right corner, Centre of the image?
- Visual Properties: Properties of object like Size, Shape, Color
- Object Taxonomy: Grouping objects based on categories. Vehicle/Animal/Human
- Action: Locating based on the actions. Drive it? Drink it?
- When to stop questionining (start guessing) can be a seperate module, however in the proposed idea, the number of questions are fixed to ‘5’
- Guesser:
- Its role is to predict the object
- Has access to the image, dialogue and the list of objects in image
A sample dialog from the dataset is shared below

Now that we got a high level understanding of the problem, how the data looks, lets check how the network is designed.
Modelling:
- Oracle:
- Single hidden layer MLP, with a Softmax layer
- Input: Embeddings of Image(I) + Cropped Object (S) + Spatial Information + Category (c) + Current Question (q) are concatened and fed to the network
- Image -> Rescaled to 224x224 -> FC8 features are extracted using VGG network
- Cropped Object: Segmentation mask -> rescale to 224x224 -> FC8 features using VGG network
- Spatial Information: To locate the object in the whole image
- Category: Convert one-hot class vector to dense category embedding using a learned look-up table
- Question: Embeddings are obtained using LSTM network
- Loss: Negative likelihood of correct answer, minimizing the cross entropy error
- Output: Yes/No/NA
- ADAM is used as optimizer, trained for 15 epochs
- Question + Category + Spatial Oracle model gave best results (21.5% error)
- Question Generator:
- Like other natural language generation tasks, HRED (Hierarchical recurrent encoder decoder) is used by conditioning with VGG features of image
- Beam search is used to find most probable question
- Input: Image Features + Questions generated so far
- Output: Follow-up question to continue the dialogue
- Guesser:
- Input: Concatenation of Image(FC8 features from VGG network) + Dialog(Variable number of question-answer pairs) features
- Single hidden layer MLP is used to get object embeddings (object category + spatial information)
- Output: Predicted Object
- Triggered after asking 5 questions
- LSTMs performed better than HRED
Performance:
- Multiple combinations of experiments were done to evaluate the best model
- Best performing model combines object category and its spatial features along with the question
- A guesser based on human-generated dialogues achieved 38.7% error (This is the best model out of all experiments)
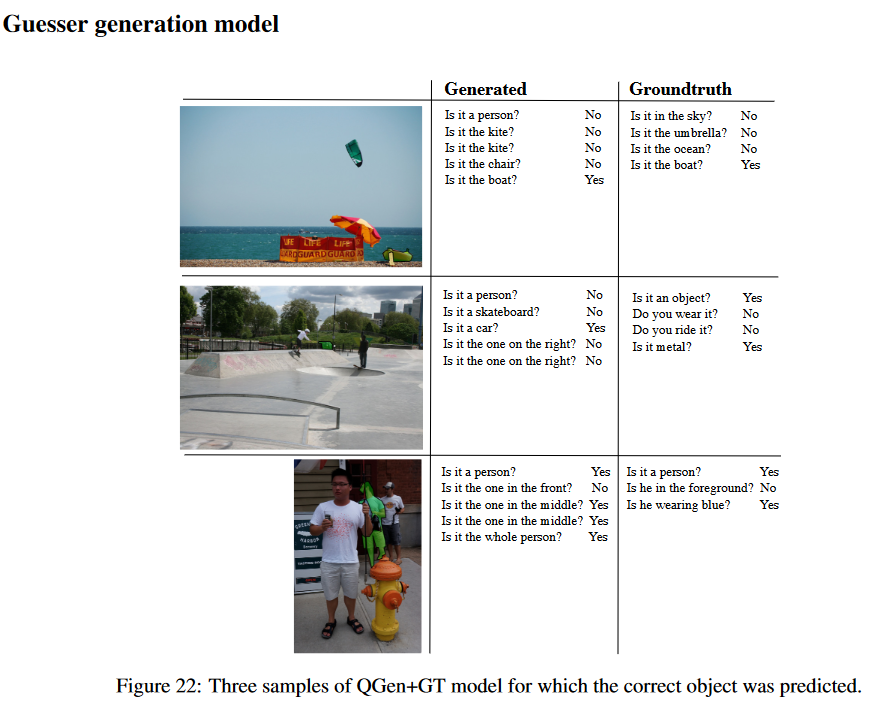
Results of the proposed guesser model is given below
Authors Observations:
- Nnumber of questions within a dialogue decreases exponentially, as players tend to shorten their dialogues to speed up the game
- Average number of questions given the number of objects within an image appears to follow a function that grows at a rate between logarithmically and linearly.
- Questioners use abstract object properties such as human/object/furniture only at the beginning of the dialogues, and quickly switch to either spatial or visual terms such as left/right, white/red or table,chair.
- Why humans not using optimal strategy? (i) no access to the list of objects in the image (ii) some may favor linear search strategy (iii) additional questions may be asked for further confirmation
- Using the Oracle’s answers while training the Question Generator introduces additional errors which significantly deteriorates performance
- Object category outperforms object crop information
- The more complex the scene is, the lower the success rate is
- Big objects are almost always found while the smallest one are only found 60% of the time. Similarly objects in the centre are found easily than at the borders.
- Including VGG features of image as input for guesser did not improve results
The baseline code is available here
Future Research Questions:
These are some of the questions that are worth pondering from the paper. Many researchers worked on the variations of the following, will discuss some of those papers in coming posts.
- Can question generator and guesser merged to a single model?
- When to stop questioning can be more dynamic (than limiting to 5 questions)
- A strategy to generate questions rather than always starting with spatial questions. Can different strategies be used for different games?
- Are there repeated questions? when to repeat, when not to repeat?
- Measure the ‘quality of information’ in questions asked and finetune these questions. Probably a better metric to evaluate the quality of questions?
- Questioner not aware of the list of objects and can only see the whole picture -> Can something be done with identifying objects by other means and use that information to generate questions?
- Can a better search mechanism than beam search used for choosing the probable question?
- Possible enhancements in maintaining the question history, long-term context
- How does the new objects/games are played which are different from objects used in training? - OOV (objects) handling
- Handling possible errors from Oracle
- Enhancements for imperfect oracle and imperfect guesser
#visual #dialog #guesswhat #oracle #questioner #guesser #task-oriented