In this blog post, I am discussing my understandings from the paper Beyond task success: A closer look at jointly learning to see, ask, and GuessWhat
Authors: Shekhar et al
Published: At NAACL 2019
Codebase Repo: Visually-Grounded Dialogue State Encoder
- Core Idea: A single model for Questioner and Guesser using multitask learning. Addresses the foundational issues of integrating visual grounding with dialogue system components
- Improved the baseline accuracy by 6-9%
- Showcased on-par results using co-operative learning (CL) and using it as an alternative to reinforcement learning (RL)
- Evaluated the linguistic quality of the generated questions across three factors (lexical diversity, question diversity, and repetitions)
The joint architecture, proposed in the paper is given below
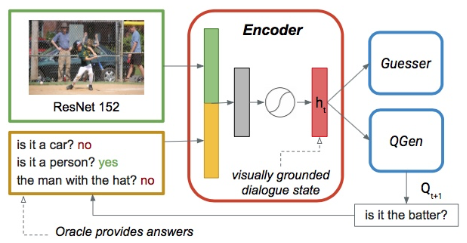
Unlike the previous models, both guesser and question generator receive same grounded dialogue state as input. Second to last layer of ResNet152 features are used in place of VGG to have better visual representation. Question generator is optimized using negative loglikelihood. By using multitask learning the optimizations of question generation module, success rate enhancing of guesser module together yields effective encoding of the input.
Dialogue Strategy:
- Questions are classified manually to different types such as category, attribute/property.
- Category is further divided into object category or a super-category
- Attributes are distinguised as color, shape, size, texture, location, and action questions
Analysis of percentage of questions per question type is given below
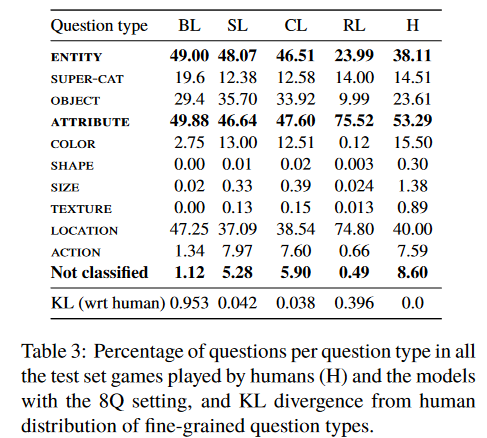
Author’s observations:
- Baseline model never asked any shape or texture questions, and hardly any size questions
- The questions generated by RL model are substantially different from human dialogues
- RL model asks many location questions
- Humans and models almost always start with an ENTITY question in particular a super-category
- When a super-category question is answered positively, humans follow up with an object or attribute question 89.56% of the time. This trend is mirrored by all models
- CL model uses a richer vocabulary and inventory of questions, and produces fewer repeated questions than RL
Food for thought:
- Rather than always starting with entity questions, can it change based on the visual scene? If so, how to feed this information to QGen Model?
- Can the number of questions be dynamic than fixed before guesser guesses?
- Setting a weightage to the category, which gets updated over the rounds so that repeated questions can be reduced
#visual #dialog #questioner #guesser #multitask #beyond #task #success #guesswhat #task-oriented