In this blog post, I am discussing my understandings from the paper Visual Dialogue State Tracking for Question Generation
Authors: Pang et al
Published: At AAAI 2020
Github Repo: Visual Dialogue
- Core Idea: Visual object representations are dynamically updated with the dialogue state
- Improved the accuracy by 10.66% and 9.33% for 5Q, 8Q over GDSE (the previous state of the art)
- Achieved SOTA performance on four different training methods including a separate and a joint Supervised Learning, a separate Reinforcement Learning and a Cooperative Learning.
- Reduced repeated questions from 50% to 21.9%
VDST Network is given below for reference
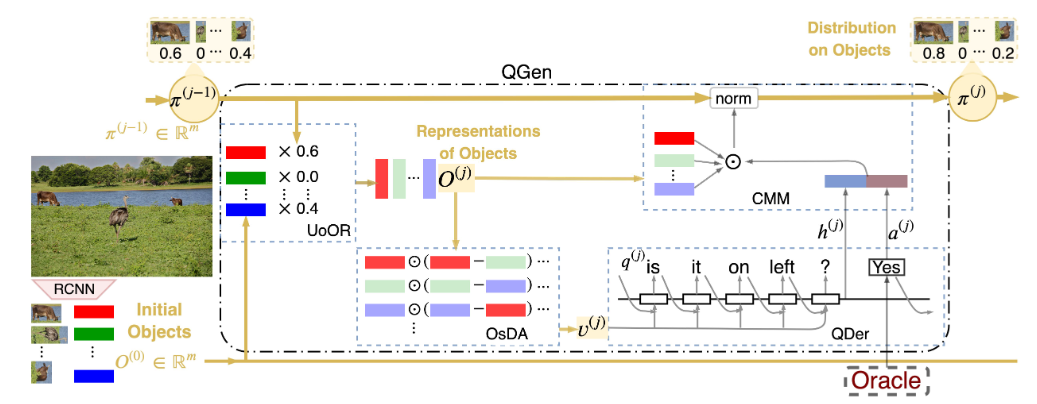
In the prior works, representations(encoded vector) for the image is unchanged(used the whole image) through out the dialogue. This paper proposed change of representation dynamically with the change of attention on different objects in the dialogue. At the beginning of the game, all objects representation will be used. As the game progresses, the attention probabilities of objects are keep changing. Thus after few rounds, the attention towards target object will be higher. As the attention is shifted to new objects/features and QGen teneded to ask new questions. This also has positive impact on reducing the repeated questions. This in turn saves the memory requirements to represent visually rich scenes.
The change in visual representation at each round of conversation is shown in the below image

Author’s observations:
- 22.38% of human dialogues in the dataset started with an entity questions. If NO is received for an entity question, model continues to ask entity questions until ‘YES’ is received
- In 67.88% of dialogues, the sequences of questions generated by proposed model implemented the above strategy.
- During last rounds of questionining, the agent focuses on asking location questions about the target object, and pays much less attention to others
Food for thought:
- Can guesser take intermediate guesses depending on the confidence from representation than waiting till the end to take a guess
- Rather than keep asking entity questions until a ‘YES’ is received, a better strategy can be used in asking questions
#visual #dialog #state #tracking #vdst #guesswhat #task-oriented