In the previous blog posts, the question generator almost always starting with entity/category questions and majority of other questions are spatial. However these kind of questions hit a block, if multiple objects share attributes, or the visual scene is complex. Also the Guesser targets a single object and does not consider the relationship among objects.
Today’s paper Unified Questioner Transformer for Descriptive Question Generation in Goal-Oriented Visual Dialogue, focusing on building an agent that can work around through these issues. The paper also discusses about imperfectness of Oracle model
Authors: Matsumori et al
Published: At ICCV 2021
- Core Idea: Question Generator and Guessers are combined into an unified transformer
- Proposed a new task CLEVR Ask to generate descriptive questions
- Exceeds task success rate on CLEVR datasets by 20% over base lines
- Focused on attribute and location questions with referring expressions
The proposed architecture and the generated dialogues are given below
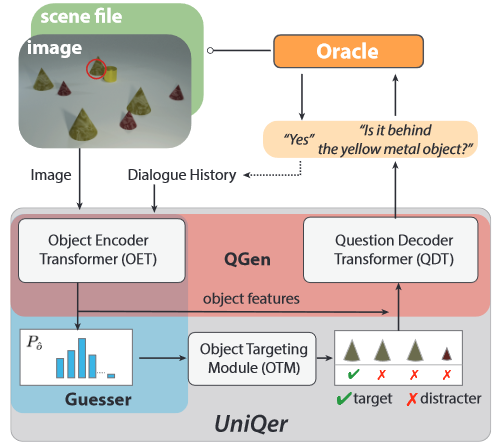
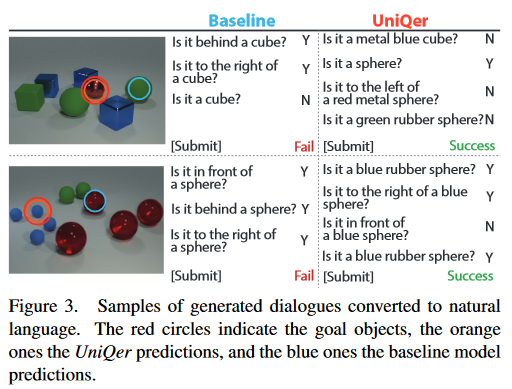
Oracle Model:
- Exhaustive information about image is available in scene file. Oracle can take advantage of it and can answer detailed/complex questions
- Questioner and Oracle converse in pseudo-language
Food for thought:
- How repetitive questions are handled? No information on the percentage of repetitive questions during testing
- The baselines are evaluated and compared on CLEVR Ask dataset. Should also explore how unified transformer works on GuessWhat Dataset and are there any improvements observed?
#visual #dialog #unified #transformer #referring #expression #clevr #ask #guesswhat #task-oriented