One of the problems that was discussed in previous blog posts was, Question Generator is not aware of the objects in the image. Hence the questions start with categories and the dialog flows if ‘Yes’ is encountered along the line. Also during the trails, it was found humans usually start with entity based questions. How to equip question generator with entity information?
Today’s paper Enhancing Visual Dialog Questioner with Entity-based Strategy Learning and Augmented Guesser deals with the same issue. Firstly, Image Captions are used to retrieve related entities for the target image. Secondly during the dialogue, at each round, it selects which entity to ask based on dialogue condition. In addition, guesser is also improved over the previous models. Entity selector module is introduced is to select which is the entity to focus in this round. Uses RL approach and unlike previous approaches no penalization used.
Authors: Zheng et al
Published: At Findings of EMNLP 2021
Codebase: Watch here
- Core Idea: A related entity enhanced questioner that follows entity based questioning strategy
- An improved guesser
- Achieved SOTA results with RL approach for GuessWhich Dataset
The proposed architecture and the results are given below
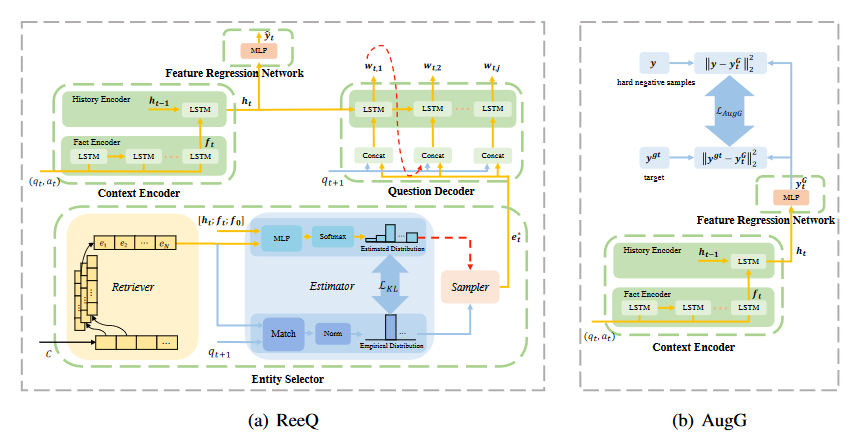
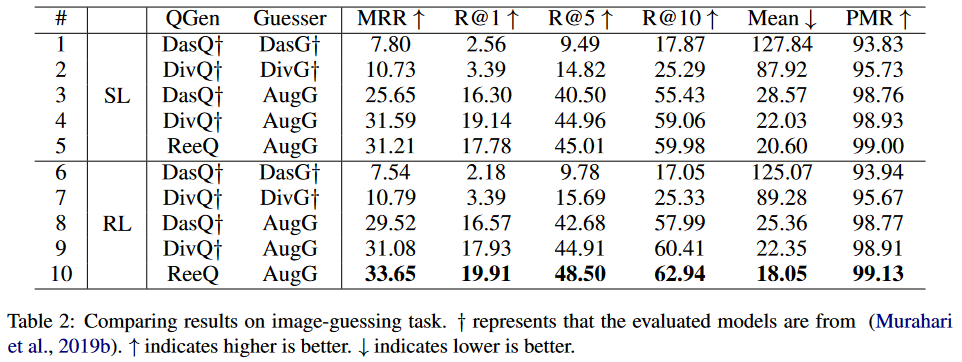
Authors observations:
- Model is able to generate constantly visually-related and informative dialogs
- Repetitive questions are reduced
- Additional time cost introdued due to entity estimation and generating entity guided questions
Food for thought:
- The model was proposed for GuessWhich Game. Can also test the same for GuessWhat game too
- Majority of GuessWhat:Question Generator starts with categorical questions: which are usually entities. Need to evaluate if there is any improvement of using entities over categorical questions
#visual #dialog #entity #guided #augmented #guesser #guesswhat #task-oriented