The series of blog posts under this theme researches on how robot’s interactions can bring the true grounding in a human-robot dialogue. I am discussing my understandings of these works. Today’s paper Collaborative Effort towards Common Ground in Situated Human-Robot Dialogue, experiments different robot interactions during a dialogue and measures its impact in bringing the common grounding.
Authors: Joyce Y. Chai et al
Published: At HRI 2014
Summary
Throughout the conversation, the robot shares information about its internal world based on its visual perception. Experiments were conducted to verify perceived grounding and true grounding for both low-effort and high-effort scenarios. High-effort scenarios show significant improvement in grounding especially when there is a high mismatch of objects.
Overview
- Research Question
- Identifying the impact of the robot’s collaborative efforts in grounding
- Motivation
- Better grounding = Better communication between human and machine
- Outcome
- Mediating Dialogue System
- Encouraging results showing high effort from the robot leads to true grounding
System Overview
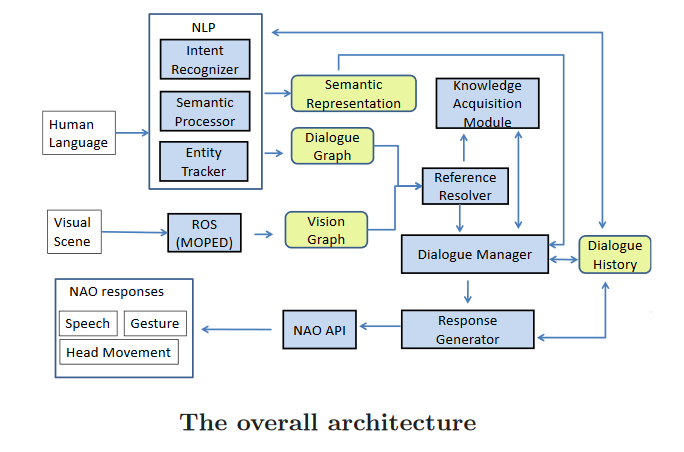
- NLP Modules
- Intent Detection, Semantic Processor, Entity Tracker
- Input: Conversation
- Output: Semantic Grounding, Dialogue Graph
- Dialogue Graph
- Nodes: Entities from dialogue
- Properties: Name, Colour, Type
- Node connections: Spatial/other references from dialogue
- Vision Graph
- Nodes: Entities from vision
- Properties: Colour, Type, Position [Can also add new properties coming from dialogue]
- Node connections: Spatial/other references from dialogue
- Knowledge Acquisition
- From reference resolver: by matching vision and dialogue graphs
- From asking confirmation question [Is the blue can Mary?]
- Dialogue Manager
- Dialogue policy based on state and its relevant action
- Response Generator
- Response by speech, gesture and head movement
Food for thought
- Dialogue Manager
- Re-examining dialogues that were failed to have a common grounding
- Any particular objects (because of their colour, the language used to describe that object, lighting conditions for that object, and their spatial reference with other objects etc.) were misrepresented?
- Any repeated dialogues [I can’t see, I don’t know] continuously for any object in a given circumstance
- Any errors in generating feedback? This leads robots not to know what the human was referring to
- Re-examining dialogues that were failed to have a common grounding
- Grounding
- Enhancing vision and dialogue graph to include more information
- In addition to true grounding, any other methods to showcase the grounding is enhanced?
- Response Generator
- Exploring other means (non-verbal modalities) for sharing information
- NLP Modules
- Intent Detection, Semantic Parser, and Entity Tracker can be enhanced as they are not exhibiting fool-proof performance
- Vision Module
- Enhanced CV module with better object detection and localization
- Knowledge Acquisition/Reasoning
- Propagating knowledge acquired in one scenario to a new scenario [Did not find a discussion on this in the paper]. How conflicting information will be handled. Scenario1: A blue can is called Mary, Scenario2: An orange can is called Matty. Can the robot able to reason, an object with so and so properties is a can and it can have multiple names, probably associated with a colour
- If the references (names) are the same for two different objects, how robot responds to questions?
Some More